What is Fog Computing?

Intro from VP
Sovereign data is not enought . user need to have a compute power and tools for processing a data. How to have a comtupation power outside of amazon or azure ? Lets discover fogs

what is fog
Fog computing is a decentralized computing infrastructure in which information, compute, storage, and operations are placed somewhere between the data source and the cloud. Like edge computing, fog computing brings the benefits and power of the cloud nearer to where data is generated and acted upon. A lot of people use the terms fog computing and edge computing mutually because both involve delivering intelligence and processing nearer to where the data is generated. This is often done to boost efficiency, though it might also be done for security and compliance reasons. The devices consist of fog infrastructure are known as fog nodes. In fog computing, all the storage capacity, computation abilities, data along with the operations are located between the cloud and the physical host. All these processes are located more towards the host. This increases processing speed as it is done almost at the place where data is generated. It enhances the efficiency of the system and is also used to ensure increased security.
When to use Fog Computing?
It is used when only selected data is required to deliver to the cloud. This selected data is selected for long-term storage and is less frequently obtained by the host. It is used when the data should be examines within a fraction of seconds that is latency should be low. It is used whenever a huge number of services need to be supplied over a large area at different geographical locations. Devices that are subjected to rigorous operations and processing must use fog computing. Basic Components of Fog Computing
Basic Components of Fog Computing
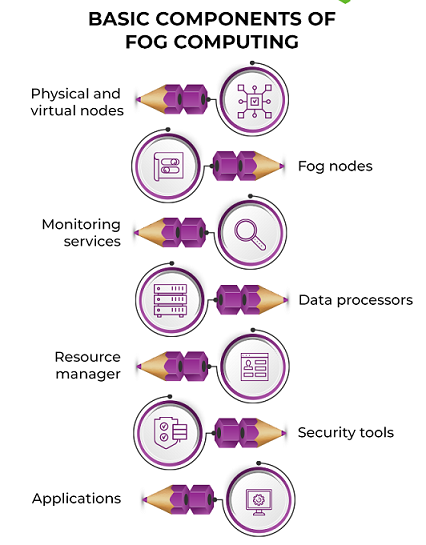
Physical and virtual nodes (end devices)
End devices work as the points of contact to the real world, be it application servers, edge routers, end devices such as smartphones and smartwatches, or sensors.
These devices are data generators and can span a huge scope of technology. This means they may have varying storage and processing capabilities and different software and hardware.
Fog Nodes
Fog nodes are independent devices that pick up the generated data. Fog nodes divided into three categories: fog devices, fog servers, and gateways.
These store important data while fog servers also determine this data to decide the course of action.
Fog devices are generally connected to fog servers. Fog gateways redirect the data between the various fog devices and servers.
This layer is important because it control the speed of processing and the flow of data.
Setting up fog nodes need knowledge of varied hardware configurations, the devices they directly control, and network connectivity.
Monitoring Services
Monitoring services generally consist of application programming interfaces (APIs) that keep track of the system’s performance and resource availability. Monitoring systems make sure that all end devices and fog nodes are up, and communication isn’t stalled.
Sometimes, waiting for a node to free up may be more costly than hitting the cloud server. The monitor takes care of such situations.
Monitors can be used to examine the current system and predict future resource demands based on usage.
Data Processors
Data processors are programs which run on fog nodes. They filter, cut, and sometimes even rebuild faulty data that flows from end devices.
Data processors are used to determining what to do with the data i.e., whether it should be stored locally on a fog server or sent for long-term storage in the cloud.
Data from various sources is homogenized for easy transportation and communication by these processors.
This is done by revealing a uniform and programmable interface to the other components in the system.
Some processors are smart enough to fill the data based on historical data if one or more sensors fail. This prevents any sort of application failure.
Resource Manager
Fog computing includes independent nodes that must work in a synchronized manner.
The resource manager allocates and deallocates resources to various nodes and arrange data transfer between nodes and the cloud. It also takes care of data backup, ensuring no data loss.
Since fog components take up some of the SLA commitments of the cloud, high availability is required.
The resource manager works with the monitor to decide when and where the demand is high. This make sure that there is no redundancy of data as well as fog servers.
Security Tools
Since fog components directly connected with raw data sources, security must be built into the system even at the ground level.
Encryption is a must since all communication need to happen over wireless networks.
End users directly send request to the fog nodes for data in some cases. As such, user and access management are part of the safety efforts in fog computing.
Applications
Applications provide real services to end-users. They use the data provided by the fog computing system to give quality service while ensuring cost effectiveness.
It is important to note that these components must be controlled by an abstraction layer that exposes a common interface and a common set of protocols for communication. This is generally achieved using web services such as APIs.
How does Fog Computing work?
Fog computing execution involves either writing or porting IoT applications at the network edge for fog nodes using fog computing software, a package fog computing program, or other tools. Those nodes nearest to the edge, or edge nodes, take in the data from other edge devices such as routers or modems, and then direct whatever data they take into the optimal location for analysis.
In connecting fog and cloud computing networks, administrators will evaluate which data is most time sensitive. The most critically time sensitive data should be analysed as close as possible to where it is created, within verified control loops.
The system will then pass data that can wait longer to be examined to an aggregation node. The characteristics of fog computing simply dictate that each type of data determines which fog node is the ideal place for analysis, depending on the ideal aim for the analysis, the type of data, and the instant needs of the user.
Fog Computing VS Edge Computing
According to the OpenFog Consortium started by Cisco, the key difference between edge and fog computing is where the intelligence and compute power are located. In a strictly foggy environment, intelligence is placed at the local area network (LAN), and data is transmitted from endpoints to a fog gateway, and then transmitted to sources for processing and return transmission.
In edge computing, intelligence and power can be either at the endpoint or a gateway. Proponents of edge computing praise its reduction of points of failure because every device independently works and determines which data to store locally and which data to send to a gateway or the cloud for the next analysis. Proponents of fog computing over edge computing say it’s more scalable and allows a better big-picture view of the network as multiple data points feed data into it. It should be noted, however, that some network engineers consider fog computing to be only a Cisco brand for one approach to edge computing.
Advantages of Fog Computing
This approach decreases the amount of data that needs to be sent to the cloud.
Since the distance to be traveled by the data is decreased, it results in saving network bandwidth.
It decreases the response time of the system.
It enhances the overall security of the system as the data resides close to the host.
It gives better privacy as industries can perform analysis on their data locally.
Disadvantages of Fog Computing
Congestion may take place between the host and the fog node due to increased traffic (heavy data flow).
Power consumption increases when another layer is located between the host and the cloud.
Scheduling tasks between host and fog nodes along with fog nodes and the cloud is challenging.
Data management becomes tedious as along with the data stored and computed, the transmission of data includes encryption-decryption too which in turn release data.
Examples and use cases of Fog Computing
Smart Homes
Smart home is one of the most common use cases of fog computing. A smart home contains technology-controlled ventilation and heating system such as the Nest Learning Thermostat, smart lighting, programmable shades and sprinklers, smart intercom systems to communicate with people indoors as well as those at the door, and a smart alarm system. Fog computing can be used to construct a customized alarm system. It can also be used to automate specific events, such as turning on water sprinklers based on time and temperature.
Smart Cities
Smart cities aim to be automated on every front, from garbage collection to traffic management. Fog computing is specifically pertinent when it comes to traffic regulation. Sensors are used at traffic signals and road barriers for detecting pedestrians, cyclists, and vehicles. Speedometers can be used to measure how fast they are travelling and how likely it is that it will result in a collision. These sensors use wireless and cellular technology to collect this data. Traffic signals automatically turn red or stay green for a long period of time based on the information processed from these sensors.
Video Surveillance
The most common example of fog computing is perhaps video surveillance, given that continuous streams of videos are large and clumsy to transfer across networks. The nature of the data involved causes latency and network issues. Video surveillance is used in malls and other large public areas, and it has also been used in many communities’ streets. Fog nodes can find anomalies in crowd patterns and automatically alert authorities if they notice violence in the footage.
Healthcare
The healthcare industry is one of the most heavily regulated industries, with regulations such as HIPAA being mandatory for hospitals and healthcare providers. This sector is always looking to create and address emergencies in realtime, such as a drop in vitals. It can be done using data from wearables, blood glucose monitors, and other health-related apps to look for signs of bodily distress. This data should not face any latency problems, as even a few seconds of delay can make a huge difference in a critical situation such as a stroke.
Conclusion
The purpose of fog Computing is to reduce processing burden of cloud computing. Fog computing is bringing data processing, networking, storage, and analytics nearer to devices and applications that are working at the network’s edge. Thus, fog Computing today’s trending technology mostly for IoT Devices.
Keep Learning 😊
Author:
Ramraje Deshmukh source : https://medium.com/@pranav.galande19/fog-computing-1ee9e9c68eea



Write a comment