Distributed Hash Tables
- Distributed Hash Tables
- How does it work
- Real life example
- Raft Consensus Algorithm
- How does it works
- Real life example
- Physical Clock
- How does it works
- Real life examples
Distributed Hash Tables
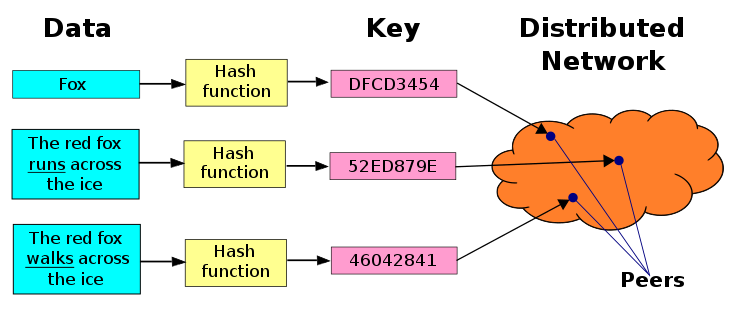
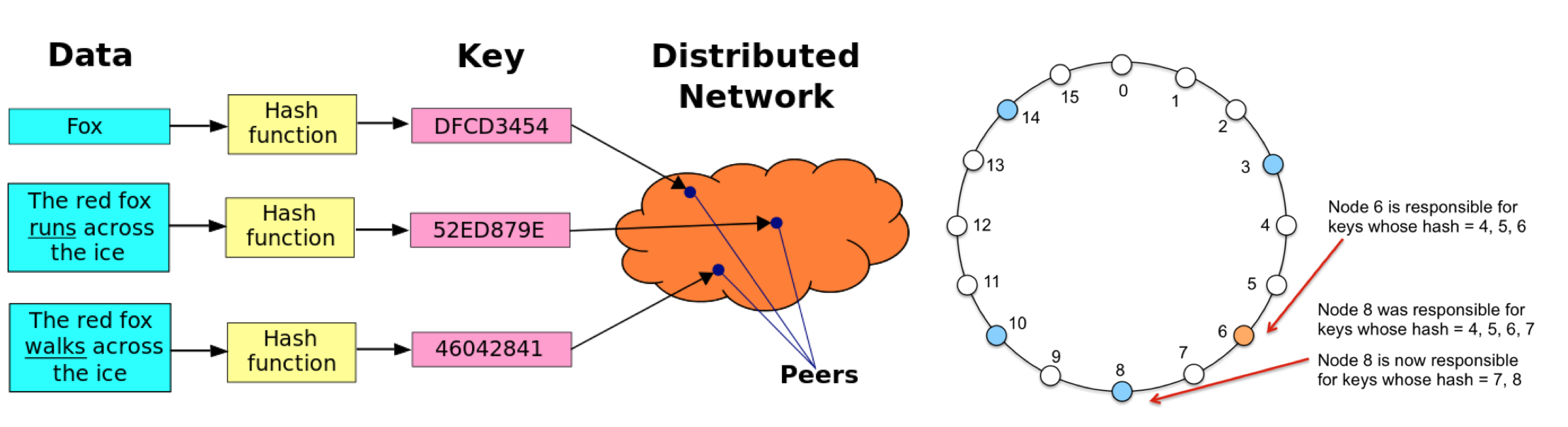
Distributed Hash Table (DHT) is a decentralized distributed system that provides a scalable and fault-tolerant way to map keys to values in a distributed network. It serves as a distributed data structure, allowing nodes in a network to find and store data efficiently without the need for centralized coordination or a single point of failure. DHTs are commonly used in peer-to-peer (P2P) networks, distributed file systems, and distributed databases.
Key characteristics and concepts associated with Distributed Hash Tables:
1. Decentralization: In a DHT, there is no central authority or centralized data repository. Instead, data is distributed across multiple nodes in the network.
2. Key-Value Storage: DHTs are used to store and retrieve key-value pairs, where each key corresponds to a value or piece of data. The DHT algorithm ensures that keys are distributed across nodes and that each node is responsible for a portion of the keyspace.
3. Scalability: DHTs are designed to scale gracefully as the network size grows. New nodes can join the network, and existing nodes can leave or fail without causing significant disruption.
4. Fault Tolerance: DHTs are fault-tolerant, meaning they can continue to operate correctly even in the presence of node failures or network partitions. Data redundancy and replication mechanisms are often used to ensure data availability.
5. Distributed Routing: DHTs employ distributed routing algorithms to locate data efficiently. Given a key, a node can determine which node in the network is responsible for that key, allowing for fast retrieval.
6. Consistent Hashing: Consistent hashing is often used in DHTs to map keys to nodes in a way that minimizes the amount of data that needs to be moved when nodes join or leave the network.
7. Load Balancing: DHTs distribute data uniformly across nodes, which helps balance the load and ensures that no single node becomes a bottleneck.
8. Data Replication: To enhance fault tolerance and data availability, DHTs may replicate data across multiple nodes, ensuring that data can still be retrieved even if some nodes fail.
9. Security: Security mechanisms such as access control and data encryption are important in DHTs, especially in public or open networks.
10. Applications: DHTs are used in various applications, including distributed file systems (e.g., BitTorrent’s distributed file system), content delivery networks (CDNs), distributed databases (e.g., Cassandra), and peer-to-peer networks (e.g., BitTorrent).
How does it work
Distributed Hash Tables (DHTs) work by distributing the responsibility for storing and retrieving key-value pairs across multiple nodes in a decentralized network. They use a combination of distributed algorithms and consistent hashing to efficiently locate data in a scalable and fault-tolerant manner. Here’s a step-by-step explanation of how DHTs work:
1. Node Initialization:
- Each node in the DHT network is assigned a unique identifier, often a hash of some characteristic like its IP address. These identifiers define the nodes’ positions in a circular keyspace, which can be represented as a ring.
- When a node joins the DHT network, it selects or is assigned an identifier that determines its position on the ring. The node may also contact some existing nodes to announce its presence.
2. Key-Value Storage:
- To store a key-value pair in the DHT, a node hashes the key using the same hashing algorithm used for node identifiers. This hashing process transforms the key into a numeric value.
- The resulting hash value determines a position on the ring. The node identifies the “closest” node in the ring to the hash value, usually the node with the nearest identifier in a clockwise direction.
- The key-value pair is then sent to the identified node for storage. This process ensures that keys are distributed across nodes consistently.
3. Key Lookup:
- When a node wants to retrieve the value associated with a specific key, it hashes the key to produce a hash value.
- The node queries the DHT to find the node that is responsible for the hash value. This is typically the node with the identifier closest to the hash value in the clockwise direction on the ring.
- If the responsible node is available and contains the requested key-value pair, it responds with the value. Otherwise, if the responsible node is unavailable or doesn’t have the data, the request is forwarded to the next closest node in the clockwise direction.
- This recursive lookup process continues until the responsible node is found, or it is determined that the data does not exist in the network.
4. Load Balancing:
- DHTs aim to distribute data uniformly across nodes in the network to maintain load balance. As new nodes join or existing nodes leave, the consistent hashing mechanism is used to reassign responsibilities for keys.
- This rebalancing ensures that the network remains efficient and evenly loaded even in dynamic environments.
5. Fault Tolerance:
- DHTs are designed to be fault-tolerant. If a node becomes unavailable due to failure or disconnection, the DHT network can continue to operate, and data can still be retrieved from other nodes.
- Data redundancy and replication are often used to enhance fault tolerance. Multiple nodes may store copies of the same data, reducing the risk of data loss due to node failures.
6. Security:
- DHT implementations can include security mechanisms like access control, data encryption, and authentication to protect data privacy and integrity.
7. Applications:
- DHTs are used in various applications, including distributed file systems, content delivery networks (CDNs), distributed databases, and peer-to-peer networks. They provide a scalable and fault-tolerant approach to distributed data storage and retrieval.
Real life example
BitTorrent Distributed Hash Table (DHT)
BitTorrent is a popular peer-to-peer (P2P) file-sharing protocol that allows users to distribute and share large files efficiently. The BitTorrent DHT is a critical component of the BitTorrent network, enabling users to discover and connect with peers who have the same files they want to download. Here’s how the BitTorrent DHT works:
Node Initialization:
- When a BitTorrent client (a node) joins the BitTorrent network, it generates a unique identifier, typically a hash of its IP address and port number.
- The client may contact a known DHT node (often a bootstrap node) to announce its presence and request information about other nodes in the DHT network.
Key-Value Storage:
- In the context of BitTorrent, keys are usually the infohashes of torrents, which uniquely identify each torrent.
- When a user wants to share a torrent or download a torrent, their BitTorrent client generates an infohash for the torrent and stores it in the DHT.
- The client hashes the infohash to obtain a hash value, which determines the location of the responsible node in the DHT network (the node whose identifier is closest to the hash value).
Key Lookup:
- When a user wants to download a torrent, their BitTorrent client performs a DHT lookup by hashing the torrent’s infohash to find the responsible node.
- If the responsible node is online and participating in the DHT network, it can provide the IP address and port number of other peers who are also downloading or sharing the same torrent.
- If the responsible node is not online or does not have the data, the request is forwarded to the next closest node in the DHT network, and the process continues recursively until a responsive node is found.
Load Balancing and Fault Tolerance:
- The BitTorrent DHT aims to distribute torrent metadata (infohashes) uniformly across nodes to maintain load balance.
- It is designed to be fault-tolerant, so if some nodes go offline, others can still respond to DHT queries and facilitate peer discovery.
Data Replication:
- In BitTorrent’s DHT, data replication is not a primary concern because the data (torrent metadata) is expected to be available from multiple sources (peers sharing the same torrent).
- However, multiple nodes may store copies of DHT data to enhance availability.
Outcome:
In this example, the BitTorrent DHT enables users to discover and connect with peers who have the same torrents, facilitating efficient file sharing. By distributing the responsibility for storing and retrieving torrent metadata across nodes in a decentralized network, the DHT helps users locate and download files without relying on a central server.
Raft Consensus Algorithm

Raft is a consensus algorithm designed to manage distributed systems and ensure that they operate correctly in the presence of node failures and network partitions. It’s primarily used for maintaining the consistency of replicated logs in distributed systems like distributed databases, key-value stores, and fault-tolerant distributed services. Raft is known for its simplicity, understandability, and safety.
Key features and concepts of the Raft consensus algorithm include:
- Leader Election: In a Raft-based system, one node serves as the leader, while the others are followers. The leader is responsible for managing the replication of logs and making decisions on behalf of the cluster. Leader election is a key component of Raft, ensuring that only one leader exists at a time. If the leader fails, a new leader is elected.
- Term-Based: Raft operates in terms or epochs, and each term begins with a leader election. Terms help nodes distinguish between the current leader and leaders from previous terms.
- Log Replication: Raft ensures that all nodes have consistent logs. Clients submit log entries to the leader, which replicates the entries to followers. Once a majority of nodes have acknowledged the receipt of an entry, it’s considered committed, and the leader can apply it to its state machine.
- Safety Properties: Raft is designed with a focus on safety, ensuring that data consistency is maintained even in the presence of failures. It uses mechanisms like leader election and quorum-based decision-making to prevent issues like split-brain scenarios.
- Leader Heartbeats: The leader sends periodic heartbeats to followers to maintain its leadership. If a follower does not receive a heartbeat for a certain period, it may start an election to become the new leader.
- Quorums: Raft uses quorums (majorities) to make decisions. For a log entry to be considered committed, it must be replicated to a majority of nodes in the cluster. This ensures that at least one node in the cluster has the latest committed log entry.
- Leader-Based State Machine: In a Raft cluster, each node has a state machine that processes commands or requests. The leader is responsible for making decisions about which commands to execute and replicating those commands to followers.
- Membership Changes: Raft supports dynamic changes to the cluster membership. Nodes can be added or removed without stopping the entire system. This is useful for scaling or replacing failed nodes.
- Log Compaction: Over time, Raft logs can grow large. Log compaction mechanisms can be employed to remove redundant or outdated log entries while preserving the overall consistency of the system.
- Applications: Raft is used as the basis for distributed systems and databases like etcd, Consul, and CockroachDB, where maintaining consistency and high availability is crucial.
Raft simplifies the complexities of distributed consensus by providing a clear and understandable algorithm. It is often favored for scenarios where ease of implementation and operational reliability are key considerations. While Raft is designed to provide strong consistency, it may be less performant than algorithms like Paxos in some cases. However, its simplicity makes it a popular choice for building reliable distributed systems.
How does it works
The Raft consensus algorithm works by ensuring that a distributed system’s nodes can agree on a single, consistent state even in the presence of failures and network partitions. Raft operates through a set of carefully defined rules and procedures, and its key components include leader election, log replication, and safety mechanisms. Here’s a detailed explanation of the working mechanism of Raft:
Leader Election:
- Raft designates one node as the leader and the rest as followers. The leader is responsible for managing the replication of logs and making decisions on behalf of the cluster.
- Initially, all nodes start as followers. To elect a leader, each node uses a randomized timer called the election timeout.
- When a follower doesn’t receive a heartbeat message (sent by the leader) within its election timeout, it transitions to the candidate state and starts a new election.
- During an election, a candidate requests votes from other nodes in the cluster. Nodes grant their votes to the candidate if they haven’t voted for anyone else in the current term.
- A candidate becomes the leader if it receives votes from a majority of nodes. The leader then sends heartbeat messages to establish its authority and prevent new elections.
Log Replication:
- The leader manages the replication of log entries. Clients send their requests to the leader.
- When the leader receives a client request, it appends the request to its log and sends the log entry to followers for replication.
- Followers append the log entry to their own logs when they receive it.
- Once a log entry has been replicated to a majority of nodes (a quorum), it is considered committed. Committed entries are then applied to the state machine of each node.
Safety and Consistency:
- Raft ensures safety and consistency by requiring that a majority of nodes agree on log entries before considering them committed.
- This guarantees that only one leader can exist at a time and prevents scenarios where multiple leaders could emerge and cause data inconsistencies.
Leader Heartbeats:
- The leader continuously sends heartbeat messages to followers to maintain its leadership. These heartbeats serve as a signal to followers that the leader is still active and prevent follower nodes from initiating new elections.
Term-Based Operation:
- Raft operates in terms or epochs, each with its own leader and log. Each term begins with an election.
- To distinguish between logs from different terms and avoid using outdated information, the term number is included in messages.
Handling Failures:
- Raft is designed to handle node failures gracefully. If the leader fails, followers detect the absence of heartbeats and initiate leader elections.
- Clients can retry their requests with another node if the leader is unavailable, and the node will redirect the client to the current leader.
Cluster Membership Changes:
- Raft supports dynamic changes to the cluster membership, allowing nodes to be added or removed without stopping the entire system.
- These membership changes are carefully coordinated to maintain consistency and prevent disruptions.
Log Compaction:
- Over time, Raft logs can grow large. Some implementations employ log compaction mechanisms to remove redundant or outdated log entries while preserving consistency.
In summary, Raft’s working mechanism relies on leader election, log replication, and safety mechanisms to ensure that a distributed system operates reliably and maintains data consistency. Raft’s rules and procedures are designed to be understandable and practical, making it a popular choice for building fault-tolerant and distributed systems.
Real life example
Distributed Databases:
Explanation: Distributed databases like Apache Cassandra and etcd use Raft to ensure data consistency and fault tolerance. In a distributed database, data is typically partitioned and distributed across multiple nodes for scalability and availability. Raft helps maintain consistency among these distributed nodes.
- Leader Election: Raft ensures that only one node in the database cluster serves as the leader at any given time. The leader coordinates read and write operations, ensuring consistency.
- Log Replication: When a client submits a write operation to the leader, the operation is appended to the leader’s log and replicated to follower nodes. Once a majority of nodes have committed the operation, it is applied to the database.
- Safety: Raft’s safety mechanisms prevent situations where multiple nodes believe they are leaders, preventing data inconsistencies.
Distributed File Systems:
Explanation: Distributed file systems like Hadoop HDFS and Ceph use Raft for managing metadata and ensuring data availability. In such systems, maintaining consistency in file metadata and ensuring high availability are critical.
- Leader Election: Raft ensures that one node is the leader responsible for managing file system metadata, such as directory structures and file attributes.
- Log Replication: When a client creates, modifies, or deletes a file, the metadata changes are logged on the leader and replicated to follower nodes. This guarantees that all nodes have consistent metadata.
- Safety: Raft prevents scenarios where multiple nodes believe they are leaders, preventing metadata inconsistencies and ensuring data integrity.
Distributed Key-Value Stores:
Explanation: Distributed key-value stores like Consul and etcd use Raft for service discovery, configuration management, and distributed locking. These stores are used to store and manage key-value pairs across multiple nodes in a network.
- Leader Election: Raft ensures that one node serves as the leader responsible for managing key-value data. This leader coordinates reads and writes to maintain consistency.
- Log Replication: When clients update or read key-value pairs, the leader records these operations in its log and replicates them to followers. Once a majority of nodes commit the updates, the changes are applied to the key-value store.
- Safety: Raft guarantees that only one leader exists and that followers eventually apply the same set of updates, ensuring consistent key-value data across the distributed store.
Physical Clock
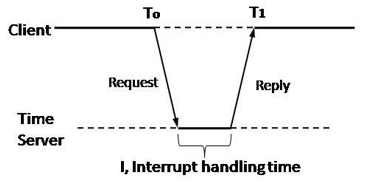
Physical clock, in the context of computer science and distributed systems, refers to a clock that derives its timekeeping from a physical phenomenon, such as the oscillations of a quartz crystal in a traditional wristwatch or the vibrations of atoms in atomic clocks. Physical clocks are characterized by their high accuracy and precision and are used as a basis for measuring time in various computing and communication systems.
Key points about physical clocks:
- Accuracy: Physical clocks are highly accurate and are capable of measuring time with great precision. They are typically used as a reference for timekeeping in various applications, including those that require synchronization.
- Types of Physical Clocks: There are different types of physical clocks, including atomic clocks (e.g., cesium atomic clocks and hydrogen maser clocks), which are among the most accurate timekeeping devices known. Other types include quartz crystal clocks and rubidium atomic clocks.
- Synchronization: Physical clocks are often used as a reference for synchronizing other clocks in distributed systems. Synchronization is essential in scenarios where multiple devices or nodes need to coordinate their actions or maintain consistent timestamps.
- Network Time Protocol (NTP): NTP is a widely used protocol for synchronizing the time of computers and network devices over the Internet. It relies on physical clocks, such as atomic clocks, as reference sources to provide accurate time synchronization.
- Global Positioning System (GPS): GPS satellites are equipped with atomic clocks, and GPS receivers use signals from these satellites to determine precise time and location information. This is crucial for navigation, scientific research, and various applications that require accurate timestamps.
- Distributed Systems: In distributed systems, physical clocks play a role in determining the order of events and maintaining consistency. Logical clocks, such as Lamport clocks or vector clocks, are often used in conjunction with physical clocks to capture causality relationships among events.
- Timestamps: Physical clocks are used to generate timestamps that indicate when events occur. These timestamps are crucial for logging, debugging, and analyzing the behavior of distributed systems.
- Clock Drift: While physical clocks are highly accurate, they can experience small discrepancies in their timekeeping due to factors like temperature variations and aging. These discrepancies are known as clock drift and need to be accounted for in some applications.
In summary, physical clocks are timekeeping devices that rely on physical phenomena to maintain accurate and precise time. They serve as a reference for synchronization and timestamping in various computer systems, including distributed and networked environments. Their accuracy and stability make them essential for ensuring reliable and coordinated operation in a wide range of applications.
How does it works
physical clock works by utilizing a physical phenomenon or process that occurs at a regular and predictable rate to measure time. The accuracy and precision of a physical clock depend on the stability and reliability of the chosen physical process. Here’s a simplified explanation of how physical clocks work:
Physical Phenomenon: Physical clocks are built around a specific physical phenomenon that exhibits consistent behavior over time. Common physical phenomena used in clocks include:
- Quartz Crystals: Quartz crystal oscillators are widely used in many electronic devices, including wristwatches and computer hardware. When an electrical voltage is applied to a quartz crystal, it vibrates at a very precise frequency, typically in the megahertz range. The oscillations of the quartz crystal serve as a reference for measuring time.
- Atomic Transitions: Atomic clocks, such as cesium atomic clocks and hydrogen maser clocks, rely on the vibrations or transitions of atoms. For example, cesium atomic clocks measure the vibrations of cesium atoms when exposed to microwave radiation. These vibrations occur at a highly stable and reproducible frequency, making them extremely accurate.
- GPS Signals: GPS satellites carry highly accurate atomic clocks on board. GPS receivers on Earth use signals from multiple satellites to determine their precise position and time. By triangulating signals from several satellites, the receiver can calculate its position and maintain an accurate time reference.
Counting Cycles: Once the physical phenomenon is established, the clock mechanism counts the cycles or oscillations of the phenomenon to measure time. In the case of quartz crystals, the clock circuit counts the number of vibrations (oscillations) per second. For atomic clocks, it counts atomic transitions or vibrations.
Timekeeping Circuitry: The clock may include electronic circuitry to measure and display the time. This circuitry typically includes components like counters and dividers to convert the high-frequency oscillations into more manageable time units, such as seconds, minutes, and hours.
Accuracy and Calibration: Physical clocks are calibrated and adjusted to ensure their accuracy. This calibration may involve fine-tuning the clock’s circuitry to compensate for factors like temperature variations that can affect the clock’s performance. Atomic clocks, in particular, undergo rigorous calibration and maintenance to maintain their high accuracy.
Synchronization: In some applications, physical clocks are synchronized with other clocks to maintain a consistent and coordinated time reference. Synchronization can be achieved through methods like the Network Time Protocol (NTP), which uses reference clocks (e.g., atomic clocks) to distribute precise time information across networks.
Display: In consumer devices like wristwatches and wall clocks, the time measurement is displayed using analog or digital displays. In more complex applications, such as scientific research and navigation systems, the time information may be used for various calculations and measurements.
In summary, physical clocks rely on the stable and predictable behavior of physical phenomena, such as quartz crystal oscillations or atomic transitions, to measure time accurately. The counting of cycles of these phenomena forms the basis for timekeeping, with additional circuitry and calibration to ensure precision. Physical clocks are used in a wide range of applications, from everyday consumer devices to critical systems where accurate timekeeping is essential.
Real life examples
GPS Satellites and GPS Receivers:
Explanation: The Global Positioning System (GPS) relies on atomic clocks aboard GPS satellites and GPS receivers on Earth to determine precise time and location information.
- GPS Satellites: GPS satellites in orbit around Earth are equipped with highly accurate atomic clocks. These clocks continuously emit signals that include the satellite’s precise location and the current time according to the satellite’s clock.
- GPS Receivers: GPS receivers on the Earth’s surface receive signals from multiple GPS satellites. By comparing the arrival times of signals from different satellites, the GPS receiver can calculate its exact position and the precise time. This enables applications such as navigation, mapping, and location-based services.
- Importance of Accurate Time: Accurate timekeeping is critical in GPS because small timing errors can lead to significant location errors. GPS receivers rely on the precise time information provided by the atomic clocks in satellites to perform accurate calculations.
Network Time Protocol (NTP) Servers:
Explanation: Network Time Protocol (NTP) servers use physical clocks, often synchronized with highly accurate atomic clocks, to provide synchronized and precise time to computer networks and devices.
- NTP Servers: NTP servers, equipped with accurate reference clocks, distribute time information to other devices on a network. These reference clocks may include atomic clocks or GPS receivers that provide highly stable and reliable time references.
- Synchronization: NTP clients on computers and networked devices periodically query NTP servers to synchronize their system clocks. By adjusting their clocks to match the time provided by the NTP server, devices across a network can maintain accurate and synchronized time.
- Applications: Synchronized time is crucial for various applications, including financial transactions, network logging, cybersecurity, and ensuring coordination and consistency in distributed systems.
Scientific Experiments and Research:
Explanation: In scientific research and experiments, physical clocks play a vital role in accurately measuring and recording time-related data.
- Particle Accelerators: Experiments conducted in particle accelerators, such as the Large Hadron Collider (LHC), rely on precise timing to measure the interactions of subatomic particles. Atomic clocks and highly accurate timekeeping are essential for coordinating experiments and recording data.
- Astronomy: Astronomical observatories and telescopes use accurate timekeeping to record celestial events and phenomena, including the timing of planetary transits, lunar eclipses, and other celestial events.
- Environmental Monitoring: In environmental science and monitoring, precise timing is essential for recording data related to weather patterns, climate change, and geological events. Accurate timestamps enable researchers to analyze data and make predictions.
- Physics and Engineering: Various physics experiments, such as studies of atomic and molecular behavior, require precise time measurement. Additionally, engineering tests and experiments often rely on synchronized clocks for data analysis.
In these examples, physical clocks, often with high accuracy and synchronization capabilities, are critical for precise time measurement and coordination in applications ranging from navigation and network synchronization to scientific research and experiments.
If you found this article helpful, please don’t forget to hit the Follow 👉 and Clap 👏 buttons to help me write more articles like this.
Thank You 🖤
Thank you for Reading !! 🙌🏻😁📃, see you in the next blog.🤘
About the Author:
Name: Gurpreet Singh
Job Role: Senior SRE
Mail : gurpreet.singh_89\[@\]outlook.com
🚀GitHub : https://github.com/supersaiyane
🚀Linked-in : https://www.linkedin.com/in/gurpreetsinghpal/
🚀Medium: https://medium.com/@gurpreet.singh_89
🚀Subscribe me @ : https://medium.com/@gurpreet.singh_89/subscribe
🚀Tech-Blog: https://www.linkedin.com/company/techbulletin
The end ✌🏻 Source : https://medium.com/@gurpreet.singh_89/exploring-key-distributed-system-algorithms-and-concepts-series-9-distributed-hash-tables-dht-76bfd2519695

Write a comment