Consistent Hashing
Problem statement:
You want to add cache server to reduce the load on the database and serve the data faster. Given a set of nodes forming a cluster of cache servers, how do you identify where is the data for a particular key?
This blog will build up on the solution for the above problem statement. We will start with a simple solution, identify the problems that can happen and try to improve upon it in the next iteration.
Let’s dive in.
Let’s say the data that you want to cache is not very big and can easily fit into one machine. You start with a single cache server. Simple option is to use a hash table which maps a given key to a value. To retrieve any key, the requests will be directed to the same cache server.
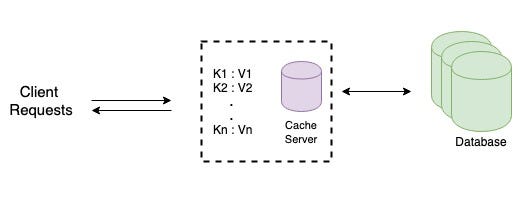
You want to scale up now
Your application has started to get traction and you realise that it’s not possible to hold the cache in a single machine and you would like to add more cache servers. You would now need to split the hash table onto multiple servers.
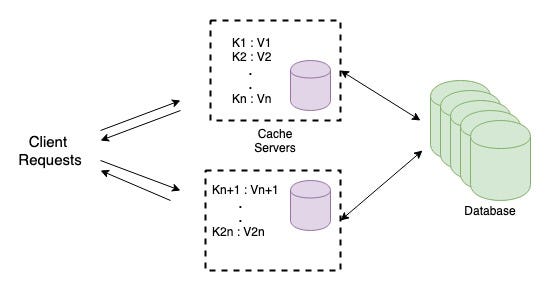
But.. How do you know which cache server holds the data for a given key ?
A simple solution would be to query all the cache servers for the given key. The cache server holding the data would return the value of the key and others would return empty. This solution has two major drawbacks.
- All the cache servers will be queried for each request. In this case the load will not be distributed among the servers.
- Latency in one of the server(which holds the data for a subset of users) will affect all the users.
Hashing
An improved solution would be to identify the node on which the data resides for the particular key. You can take the hash of the key and modulo the number of servers hash(key) % (no of servers)to distribute the keys. This approach is called the Hash Partitioning algorithm.
For the sake of simplicity, let’s assume we have 4 key value pairs. Each key represents the name of the user and the value represents the age.
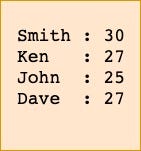
The figure given below explains how the keys will be distributed if we had three cache servers.
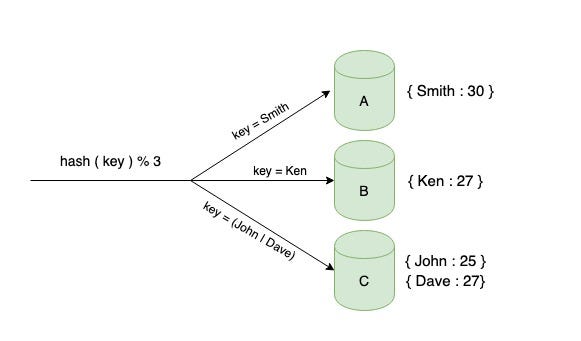
To retrieve a key, you can hash the key and mod the number of servers to determine which server holds the key. This is a better solution than the previous approach where you need to query all the nodes to get the value for a given key.
All goes well until you might need to add cache servers or if any of the existing cache servers crashes or becomes unavailable.
What happens when a node crashes? Say server ‘C’ crashes. The keys that were mapped to server C now needs to be distributed to the remaining servers. What happens to the keys that were mapped to servers ‘A’ and ‘B’? They will also be remapped. Why? Remember the routing algorithm? We take the hash of the key and mod the number of servers. Now the number of servers has changed from 3 to 2.
Request to retrieve a key say ‘Smith’ will be redirected to the server ‘B’ where as the data for it originally resided on server ‘A’. This will lead to a cache miss and the data needs to be fetched again from the database.
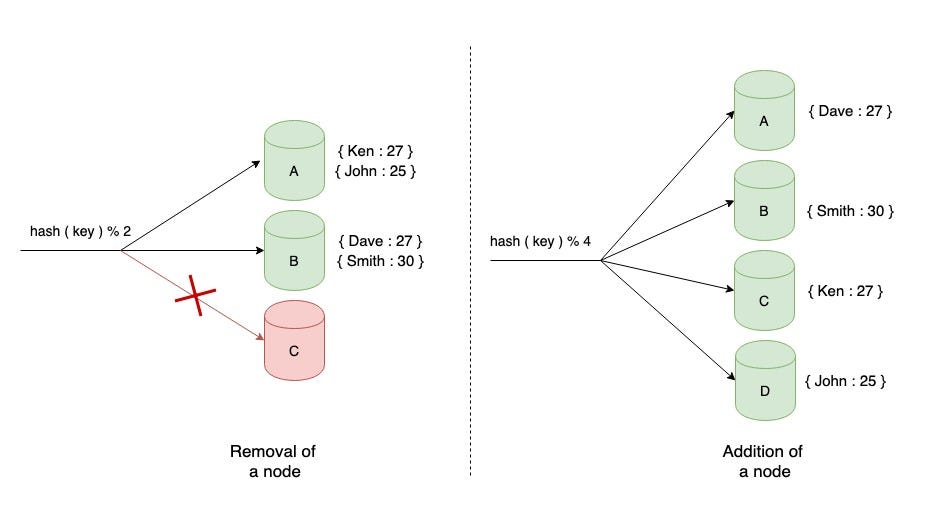
Similarly for all the keys, there will be frequent cache misses and many users whose data has already been cached will start to see problems. The original data needs to be sourced from the database again. This will increase the load on the database. In distributed systems where node failures are common, the process of building the cache every time a failure occurs will lead to a degraded performance of the application. The same concept applies when you add a cache server.
We need a hashing solution which is independent of the number of servers and at the same time should have minimal impact during scaling up/down horizontally.
Consistent Hashing
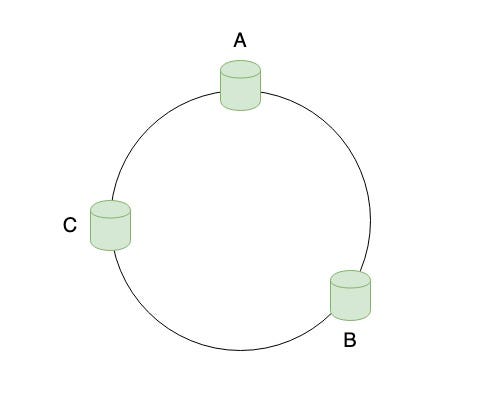
Consistent Hashing is a distributed hashing algorithm that is independent of the number of servers. It maps the servers and the keys to a hash ring. There are infinite number of points on the ring where the keys can be mapped now.
The servers can be mapped to random locations in the ring or a hash function can be used to find the location of the server on the ring. The ring is assumed to be ordered. As you traverse clockwise along the ring, the hash location increases.
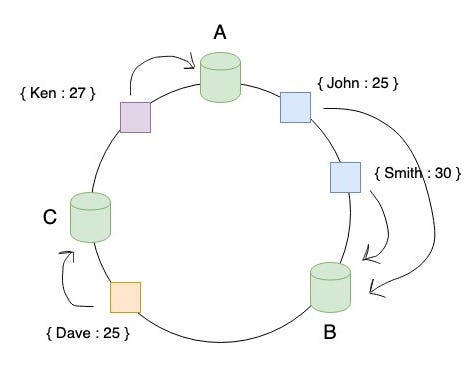
Similarly, you map all the keys to a point in the ring using the same hash function that was used to map the servers.
How do you decide which server the key belongs to? First, map the key to the hash ring. Start from the location of the key and traverse clockwise. Assign the key to the server that comes first in clock wise traversal.
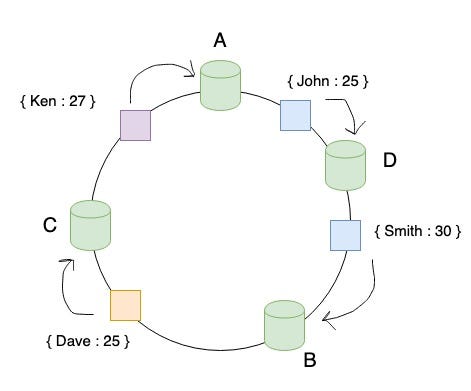
What happens when you add new cache servers? Let’s say we add one server ‘D’ and it gets mapped in between the servers ‘A’ and ‘B’ in the ring. Only the keys which fall in between the servers ‘A’ and ‘D’ will be remapped to server ‘D’ and all the remaining keys will be untouched. This is the beauty of Consistent Hashing. Only a part of the keys needs to be remapped as compared to all the keys in the Hash Partitioning algorithm.
What happens when a node crashes or becomes unavailable? The below figure shows the case when server ‘B’ has crashed. The keys which were earlier mapped to server ‘B’ will be rehashed to server ‘C’ ( the next server in clockwise direction) and the remaining keys will be untouched.
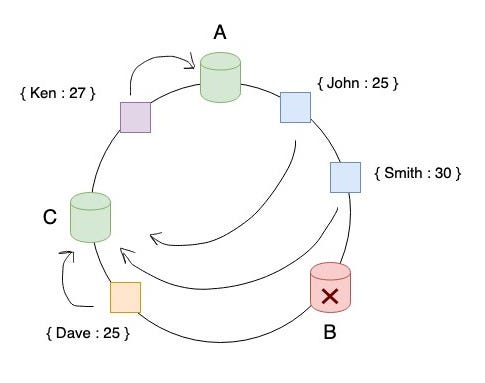
Voila! Your hashing logic has improved with Consistent Hashing and now addition/removal of nodes have lesser impact as compared to the Hash Partitioning algorithm.
But the above solution works well as long as we assume that the data is distributed uniformly. You realise that,
Practically, data is not distributed uniformly , rather it’s randomly distributed.
What are the issues that can be caused by random distribution of data? This might lead to non uniform distribution of data among the cache servers. In the below figure, you can observe that most of the keys gets mapped to server ‘B’ and if the access pattern of these keys are more frequent than the others, the server ‘B’ will see more requests while the other servers ‘A’ and ‘C’ will remain idle or under-utilised. This leads to what is called in distributed systems as hotspots.
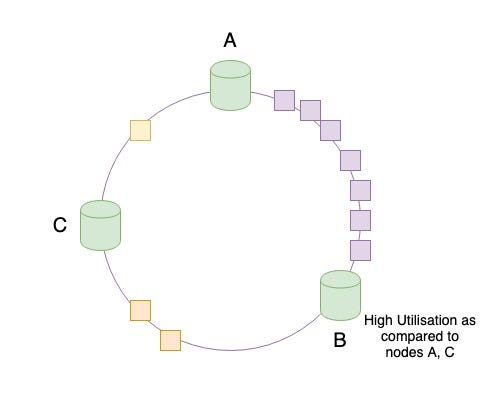
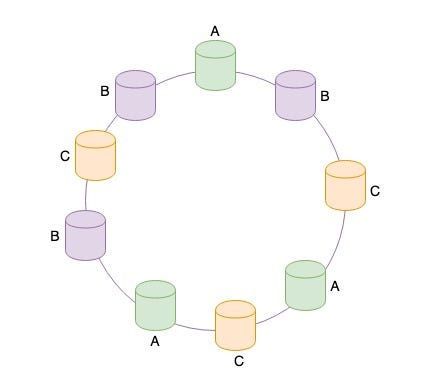
**How to avoid hotspots?
**Instead of mapping a server to one position in the ring, we can map a single server to multiple positions on the hash ring. We add virtual replicas of the actual servers in the ring. The keys will be distributed more uniformly across the cache servers now.
Conclusion
In distributed systems, as you scale up/down horizontally, building the cache each time is computationally expensive. Consistent Hashing minimizes the impact by remapping only a certain number of keys rather than all the keys as compared to the Hash Partitioning algorithm.
Moreover it is essential to distribute the load evenly among all the cache servers. Consistent Hashing solves this by adding virtual replicas of the original servers to the hash ring.
Thanks for reading this blog. Hope you found this useful. Please leave your comments below if you have any questions or suggestions. source : https://medium.com/@animeshblog/consistent-hashing-d23379273ade
Write a comment