Day 115: Building Intelligent Historical Data Archiving
- Day 115: Building Intelligent Historical Data ArchivingWhat We’re Building Today
- Core Concepts: The Enterprise Data Lifecycle
- Context in Distributed Systems
Day 115: Building Intelligent Historical Data Archiving What We’re Building Today
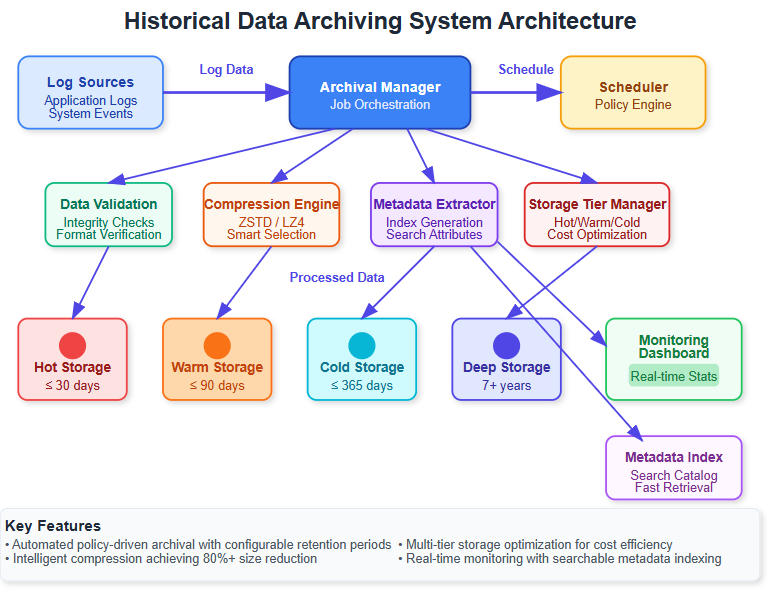
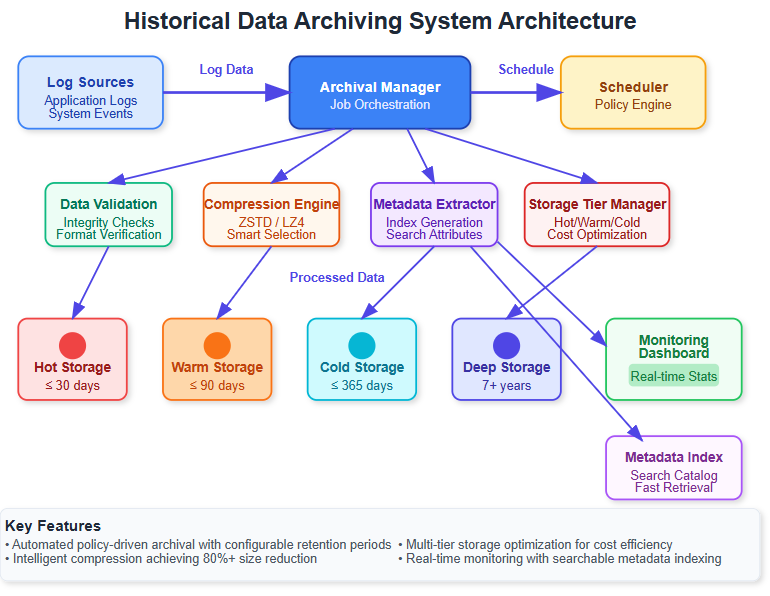
Today we’re implementing an intelligent archiving system that automatically moves aging log data to cost-effective long-term storage while maintaining instant searchability. Think Netflix’s recommendation engine - they archive billions of viewing logs but can instantly retrieve patterns from years of data when needed.
Key Implementation Points:
-
Automated archival policies triggered by age, size, and access patterns
-
Multi-tier storage architecture (hot → warm → cold → glacier)
-
Intelligent compression reducing storage costs by 80%
-
Metadata preservation enabling lightning-fast archive searches
-
Batch processing engine handling millions of logs efficiently
Core Concepts: The Enterprise Data Lifecycle
Storage Tier Intelligence
Modern enterprises operate on the “data temperature” principle. Fresh logs (hot data) need millisecond access, while year-old compliance logs (cold data) can tolerate minutes. Our archiving system automatically graduates data through temperature zones based on usage patterns.
Compression Strategies That Scale
Raw logs contain massive redundancy. Our system applies different compression algorithms per data type - JSON logs get schema-aware compression achieving 90% reduction, while binary logs use general-purpose algorithms optimizing for speed over ratio.
Metadata-First Architecture
The secret to fast archive retrieval isn’t storing everything - it’s storing the right index. Our system generates searchable metadata during archival, enabling instant queries without touching actual archived data.
Context in Distributed Systems
Real-Time Production Applications
Banking systems archive transaction logs for regulatory compliance while maintaining sub-second fraud detection on recent data. E-commerce platforms store user behavior logs for machine learning while keeping active session data instantly accessible.
Component Integration
Yesterday’s lifecycle policies act as triggers for today’s archival engine. Tomorrow’s restoration service will leverage today’s metadata indexing for lightning-fast data retrieval.
[
{kind=link}
Read more You can include dynamic values by using placeholders like: https://drewdru.syndichain.com/articles/cdb6e201-18b3-4ffc-961c-747430ff08e7 , Drew Dru, https://sdcourse.substack.com/p/day-115-building-intelligent-historical , drewdru, drewdru, drewdru,
drewdru These will automatically be replaced with the actual data when the message is sent. https://drewdru.syndichain.com/articles/cdb6e201-18b3-4ffc-961c-747430ff08e7 drewdru
Write a comment