Day 113: Implementing Tiered Storage for Log Data
Day 113: Implementing Tiered Storage for Log Data Working Code Demo:
Today’s Build Agenda
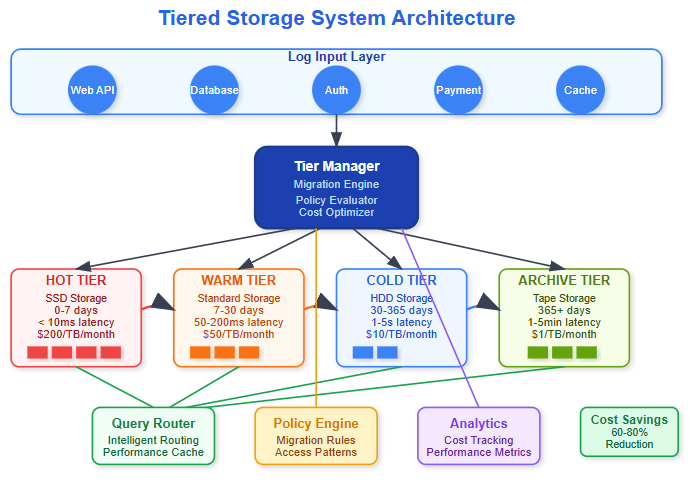
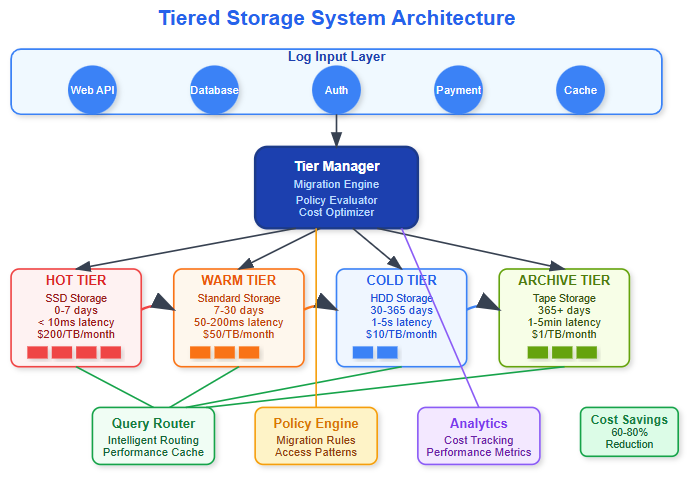
You’ll implement an intelligent tiered storage system that automatically moves log data across four storage tiers based on age, access patterns, and cost optimization. This enterprise-grade feature reduces storage costs by 60-80% while maintaining query performance.
What We’re Building:
-
Hot Tier: Recent logs (0-7 days) on high-performance SSD storage
-
Warm Tier: Moderately accessed logs (7-30 days) on standard storage
-
Cold Tier: Rarely accessed logs (30-365 days) on low-cost storage
-
Archive Tier: Long-term retention logs (365+ days) on tape/glacier storage
Core Concepts: Intelligent Data Lifecycle Management
Tiered storage transforms static data storage into a dynamic, cost-aware system. Instead of keeping all logs on expensive high-performance storage, data automatically migrates based on access patterns and business rules.
Key Design Principles:
-
Performance Degradation Acceptance: Newer logs need millisecond access, older logs can tolerate seconds
-
Cost Optimization: Storage costs decrease by 90% from hot to archive tiers
-
Transparent Migration: Applications continue working without knowing data location
-
Policy-Driven Movement: Business rules, not technical constraints, drive data movement
Real-world impact: Netflix saves millions annually by moving viewing logs from expensive NVMe storage to glacier archives after 90 days, while keeping recent data hot for recommendation algorithms.
Context in Distributed Systems
[
{kind=link}
Tiered storage sits at the intersection of storage management, cost optimization, and performance engineering. In distributed log processing, it enables horizontal scaling without linear cost increases.
System Integration Points:
-
Query Router: Determines which tier contains requested data
-
Storage Controller: Manages data movement between tiers
-
Metadata Index: Tracks data location and access patterns
-
Policy Engine: Evaluates migration rules and schedules transfers
Your tiered storage integrates with previous components: authentication (Day 112) ensures only authorized users access archived data, while upcoming lifecycle policies (Day 114) will define retention rules across tiers.
Read more You can include dynamic values by using placeholders like: https://drewdru.syndichain.com/articles/4cf5d8ea-3c3a-4d32-bf5d-f9d03dd31078 , Drew Dru, https://sdcourse.substack.com/p/day-113-implementing-tiered-storage , drewdru, drewdru, drewdru, drewdru These will automatically be replaced with the actual data when the message is sent.
Write a comment